
kafka
背景
- 网站内,要实时高效的处理海量数据
- 用户行为日志
- 业务数据库变更
- 网站上爬取的数据
- 也可以作为系统业务解耦的方式。
基本概念
- broker:指代kafka的进程,一般放一台服务器上,即真实存储消息的服务器
- topic:逻辑分区,同一类业务数据集合,可以有多个topic
- partition: 物理分区,实际存储每个topic的消息,具体位置是在broker上,每个broker上可能有多个topic的不同分区。
kafka 的系统设计
消息设计
(1)消息总长度
(2)时间戳增量:跟RecordBatch的时间戳的增量差值
(3)offset增量:跟RecordBatch的offset的增量差值
(4)key长度
(5)key
(6)value长度
(7)value
(8)header个数
(9)header:自定义的消息元数据,key-value对
存储设计
(1) .log 文件:每个分区(Partition)对应一个或多个.log文件,这些文件被称为日志段(Log Segment)
(2) .index 文件 每个日志段对应一个.index文件。
(3) .timestamp文件
kafka 的几大技术
一、kafka的高可用设计
1、多副本冗余设置
- 即一个partition不仅有leader,还有多个follow分布在不同的机器上,当一个broker宕机后,通过zk的协调,重新选出leader继续提供服务。
2、ISR列表设置
- in-sync replica,跟leader partition保持同步的follower partition的数量,从新选举的leader只能从该列表出。消息提交成功,也是在该列表中的partition 全部复制成功,才算提交了。
3、HW和LEO
- HW:代表消费者可看到的消息的offset。
- LEO:代表下一个要写入的数据的offset。
- 过程:
(1)leader 收到消息会更新自己的LEO,同时维护每个follow的LEO值
(2)follow 拉取消息时候,会带上自己的LEO值,同时能从leader拿到当前leader的HW
(3)follow 拉取到leader的HW,更新自己的HW ,策略为 min(leader的HW,自己的LEO),
(4)leader 更新HW,看自己的LEO和follow的LEO,选用min(all LEO) 作为HW。
(5)每次leader再重新选举后,都有一个版本概念,以及自己写数据的下标记录。
- 过程:
4、一些参数
- replica.lag.time.max.ms:如果某个follower的LEO一直落后leader超过了该设定的秒,那么才判定这个follower是out-of-sync,
- replica.lag.time.max.ms:规定了follower如果在该时间内仍然没有找leader发送请求,就会认为follower是out-of-sync,就会从ISR列表里移除了
- log.index.interval.bytes:在日志文件写入多少数据,就要在索引文件写一条索引,默认是4KB
二、kafka的高性能
延迟:是处理一条消息的时间
吞吐量:是整个系统处理消息的能力
1、批处理
- 平衡了延迟和吞吐量,让性能更加优秀。
2、顺序写磁盘
- 先写日志缓存(kafka内存)
- 达到时间限额,写os 的page cache
- 最后写入磁盘
3、零拷贝
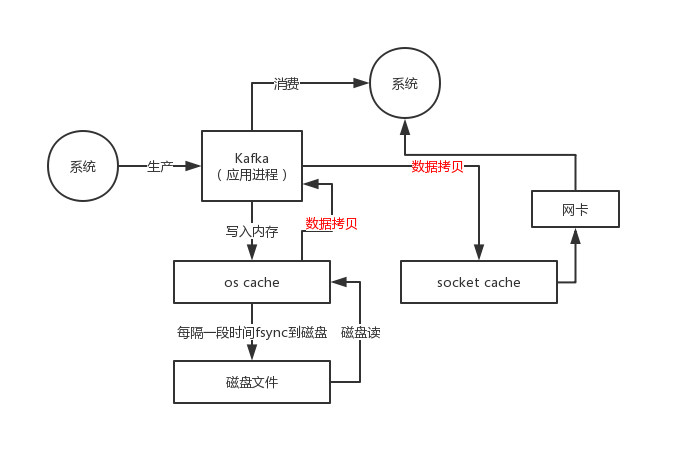
4、使用了Reactor网络通讯模型
- Acceptor:负责接受新的网络连接。 默认1个
- Processor:负责处理网络I/O操作,包括读取请求和写入响应。默认3
- Request Handler:负责处理具体的请求逻辑。 默认8个
- Selector:Java NIO中的Selector,用于监控多个Channel的I/O事件,每个Processor线程都包含一个Selector,用于监控其负责的网络连接
三、kafka的producer 高性能
1、流程
- 创建ProducerRecord,包含主题(topic)、分区(partition)、键(key)、值(value),
- 根据分区策略选择分区。
- 进入缓冲区(RecordAccumulator)中,等待批量发送。batch.size=16k,满了就发出去,linger.ms 表示超过x毫秒也会发出去。
- Sender线程负责从缓冲区中取出消息批次,遍历topic 和 parition,如果发送到同一个broker,进一步整合,最后打包成ProduceRequest。max.request.size=1m,否则就不能发送
2、核心参数
- cks=0:Producer不等待Broker的确认,消息可能会丢失。
- acks=1:Producer等待Leader确认,消息仅在Leader上持久化后返回确认。
- acks=all(或acks=-1):Producer等待所有ISR(In-Sync Replicas)中的副本确认,确保消息在多个副本上持久化后返回确认。
3、防止消息重复提交且保证分区顺序
- enable.idempotence=true:kafka提供的幂等性producer
- 原理:每个幂等性Producer实例在初始化时,会从Kafka集群获取一个唯一的Producer ID,每个消息在发送时,会被分配一个递增的序列号。序列号在每个分区内是唯一且递增的,Broker端会维护每个分区的最新序列号,并在接收到消息时进行去重和顺序检查
四,kafka的consumer 高性能
1、reblance 时机
- heartbeat.interval.ms:consumer心跳时间,
- session.timeout.ms:kafka多长时间感知不到一个consumer
- max.poll.interval.ms:如果在两次poll操作之间,超过了这个时间,
2、其他参数
- auto.offset.reset:earliest,如果下次重启,发现要消费的offset不在分区的范围内,就会重头开始消费;latest,当没有初始偏移量或当前偏移量超出范围时,消费者将从分区的最新消息开始消费
- enable.auto.commit : 开启自动提交
五、broker消息积压了怎么办
1、首先需要对kafka的topic 进行监控
2、修改topic 的配置,新增分区
3、新增消费者实例,加入消费者组
4、 优化消费者线程
5、批量拉取消息,增大拉取消息的大小限制。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 落小姐!
 wechat
wechat alipay
alipay
评论




